Usually, buffers are understood as simply something very simple – some stock of work, which can be sorted in some way. Buffers are buffers, aren’t they? But if you look at the more closely, you will find some interesting mechanisms, which can affect performance, especially in service management. In some cases, you can exploit internal structure of buffer and improve your performance. In some other cases, bad internal mechanisms of buffer can ruin the process.

You can do lots of interesting things, when you manage items in your stacks
You can say, that buffer actually is specific machine, and it has some logic inside. That logic can be primitive in some cases, but quite sophisticated in other. It is quite interesting to apply some basic principles of system programming in this, because very often mechanics is the same and mathematically those are well analyzed. You can find lots of interesting ideas in operating system design, because computer process management shows lots of logical similarities to organization management.
Random access arrays
As Audrius Vasiliauskas, excellent ToC expert and former programmer, said to me, in real companies we usually have only one kind of buffer structures – pools. The other kinds of structures are rarer and mostly are used in situations when structure of buffer is irrelevant. One most usual kind of buffers very often are called pools: we can access any chosen resource or task from them.
In computer system management and programming, those pools are called random access arrays, or indexed buffers. In such arrays we can address any randomly chosen item directly, without additional internal buffer operations. We can compare random access array with some rack, where our items are stored. We can address any item directly, without any limitation. This is exactly what does random access mean: you can randomly choose anything in the rack, and you are able to get that item without any additional work in the array.
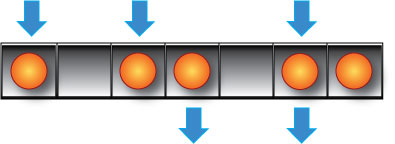
Random access array is as simple as rack. And the good point is, that we can use completely different procedures for putting into array and for getting from it.
Random access arrays are good for most cases, because we can do with them anything. We can use different procedures to put items into array, and we can use other procedures to get items from array. Everything you can imagine, can be done with arrays.
The only problem with arrays is the complexity of usage: when you have more than one choice to choose, you need procedures. And those procedures can be quite sophisticated and tricky. In many cases you can address that procedural complexity with software, but this is not always possible. Sometimes you need to get very simple, fail-proof solutions, and in this case arrays can be problematic.
Because of complexity, it is very big chance that you need some coordinator to manage those arrays. That coordinator can be real person, or can be some computer system, like ticketing system with priorities and automatic sorting by due dates.
Despite the fact, that you can implement any logic to use random access array, there are some other buffer structures, so you can have them in mind. Two most important kinds of these are stacks (FILO, First In – Last Out) and queues (FIFO, First In – First Out) buffers.
Queues or FIFO buffers
Very often you can see queues in some supermarkets. Those queues are actually buffers (client buffers for cashiers), but those buffers have strong internal structure: the one, who gets first into queue, gets out from queue first, too. When you have supermarket with several queues, you can describe that market as a system of directly addressed arrays of goods in the shelves and one array of queues (yes, that’s right: buffer of buffers). People, who get in the store, can directly access any wares, but when they get into the queue they get into the queue, isn’t it?
Queue is so easy structure, that you can get it naturally, without any thinking about it. When you see some queue in the market, you see the natural case of queue. And quite often you can say that it is the best possible choice to run: it is auto-manageable, its behavior can be predicted, it is easy choice.

You can imagine queue as tube with both ends open. The first end is for putting items and the second end is for getting items. The first item you put, the first item you get.
The problem with queues is simple: you have quite long reaction times. When you get 10 people into your queue and have 3 minutes for every person to service, the last person will be served only after half of hour. And there is a chance, that 10th customer will be your gold customer, who brings you big money. That means, it would be better to address him before the others? But you cant, if you have simple queue.
Oh, yes, you can resort your queue or address items directly. But then you will get random access array instead of simple queue. And arrays aren’t so dumb, so you will get procedures, coordinators, management software and so on. Some markets try to use ticket machines which gives possibility to manage queues. Usually things go after typical scenario: after some time those supermarkets abandon those machines and return back to their queues. Why? Because of in case of supermarkets, simple queues are the best kind of choice and any additional managing only worsens the situation.
Reaction times of queues can be easily reduced by using several queues instead of one. And so you can increase throughput.
Sometimes, when you deal with services, you can ask simple question: are you able to effectively manage internal buffer mechanisms? If that buffer seems like queue, and you have problems to manage it by direct access, and it is too complex to manage it, and if it tends to behave in FIFO way, that means you have simply queue. In this case it can be better to exploit it, but not to fight with it.
Stacks or FILO buffers
Stacks are quite rare as purposeful solutions, but actually you can see them quite often. Actually, stack-buffer is most popular kind of personal (human) buffers of service staff. And this kind of buffers have very bad manageability.
Imagine situation: some worker gets task. He starts doing it, but then somebody comes and gives him another task. So worker pushes first task further and starts doing new task. Then again, somebody comes and gives third task. Worker pushes his second task further and first task even more away and starts doing third task. After third task is completed, worker starts doing the second task and after it is completed, he completes his first task. This is how stack works. Yes, this is typical mechanism of multitasking.

Stack is like tube with one end open: you can put many items into it, but as you can get only from the side from which you put, you get only the last item. Sometimes things stuck deep in the stack and never get out.
Good point with stacks is simple: because you always work with the last task, you have really good reaction times. Your responsiveness to new tasks can be as good, as you have no load at all, despite your actual load can be quite high. And this is the reason why people tends to manage their work as stacks.
The problem is, that when you do reactive work, you always get exception (extra-high priority event) which naturally gives higher priority to new task. So new task interrupts and pushes older tasks further from completion. And the second problem is that old tasks tend to be forgotten, so them easily falls to the bottom of stack. And this is the way how you get some works overdued for months or even years, despite you’re working quite hard and fast. It is the cause of bad multitasking.
I saw very good solution, given and explained by Hans Steenpoorte. He improves processes in service companies, and one of his method is quite simple: you identify, where works last for long, create and enable sprint team of workers, who are able to make solutions for problems and this is the way to deal with those overdues.
This solution can be described as some combination of stack and queue: because organization tends to work with stack and it needs that stack (because of high responsiveness), you leave it with stack. But on the other hand, you need to do something with those overdued tasks, so you put sprint team on the other end of stack and so you get queue.
As long tasks are in queue, they are processed and not forgotten. And short tasks are on stack and them are processed with high responsiveness. This is really good solution, but look at it: it can be quite difficult to describe it as a procedure. But it is quite easy to describe it as a some buffer structure.
We can use such stack-queue structure when we need to separate reactive works from proactive ones. For example, to deal with incidents (service breaks) and problems (root causes of many incidents). I like this hack, it is really good.
Very often you will find that stack-based management is the cause of lost tasks and bad multitasking. But remember that sometimes you can’t avoid stack: for example, it is the only natural way to have escalation procedures. You need stack for both hierarchical and functional escalations, because you need to ensure that request is not lost and it is returned to person who did the escalation. So you can say that any helpdesk is always stack-based.
Sorting of buffers
At last, there is topic about sorting and resorting – this can be said as some kind of internal buffer mechanism too.
Actually, you do sorting every day. And even in solution of Hans Steenpoorte, you actually have sorting in the queue: tasks for sprint group are put into queue after assessing what is wrong with those tasks (for example, sprint group can get fresh task, if case is very important) . So you need to understand, that despite you have stacks, and arrays, and queues somewhere, you can do sorting and sometimes you can do more complex structures, and you can do almost anything you can imagine.
Sorting is the most important part of all the internal (not external) buffer management: as you set due dates (real priorities), you actually set sequences of tasks. In other words, you do sorting. But this is not always simple, because sorting is not always easy. Imagine that you have several sorting parameters and hundreds of tasks to sort – this can give you very big workload. Bur anyway, very often you need to do that sorting, because priorities change.
Things to consider: automatic management systems, like task management and project management software, can do lots of work. Those systems ease and automate sorting, so you don’t have to waste your time. But when you do some sorting manually or you try to configure some task management system, it is good to know some basic algorithms.
The first is heap sorting, which can be quite good for project environments: you can insert or move some tasks simply from one place to another, by assessing actual priorities of them. This is method is used quite often intuitively by some project managers. The only prerequisite to use heap sorting is quite big time buffers, because if you don’t have them, you will push other works from their places. In the other words, the problem is that you must have time buffers to put your tasks in the new place, without messing other tasks.
The second algorithm is partial sorting: in this case you do not actually sort all the things, but find extremes of them. For example, you find the only task where risk to have overdue is highest and move that task to the first place to do. Using such method, the buffer behaves like it is always sorted, but instead of sorting all the tasks, you do minimal sorting work, because you search for only one, most risky task. This kind of sorting is very good, when sorting is done manually and logic of sorting is complex.
Some internal buffer sorting example
I give you some example to get into management of internal buffer mechanics (actually it is some real company process). This will be case of using combined queues.
Case is interesting: company gets very big variation in size of tasks (tasks, not batches) from customers. For example, some of the tasks should be done in one hour, but some of them should be done in one month, because variation in size can be as high as thousand times. The second thing is that tasks can not be easily divided into smaller chunks, so this is not the typical case of big batches vs. small ones. On the other hand, due dates are directly related to amount of work, so this thing eases the situation.
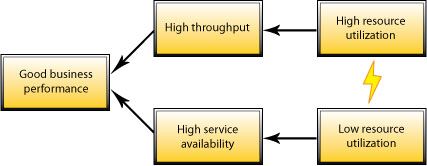
High availability services vs. maximized throughput
The problem is, that with short tasks company need to work with very high availability of services. This means, workload must be quite low to ensure that workforce is available by request. On the other hand, there is quite hard competition in prices, so you need to ensure quite high throughput to get profit. This means, that workload must be kept as high as you can. Easy solution to divide workers into two pools is problematic, because there is big variation and low predictability of task sizes. Dynamic management of group sizes would be too complex.
The solution can be seen, if you have some double-queue with internal sorting. Imagine that you have two queues: one for bigger tasks with long due dates, and the second for smaller tasks with short due dates. Bigger tasks do high throughput and the smaller ones are processed quickly. Then you say, that both queues are joined and sorted as one queue, but after sorting you still have two queues. So, actually, tasks are put in the middle of that double-queue, then are sorted by due date (which is related to amount of work), and then you have outputs in the opposite ends of that data structure. As a result, you have tasks where short reactions are needed on the left side, and maximum utilization tasks on the right side. And then you put your workers into some sorted array and run.
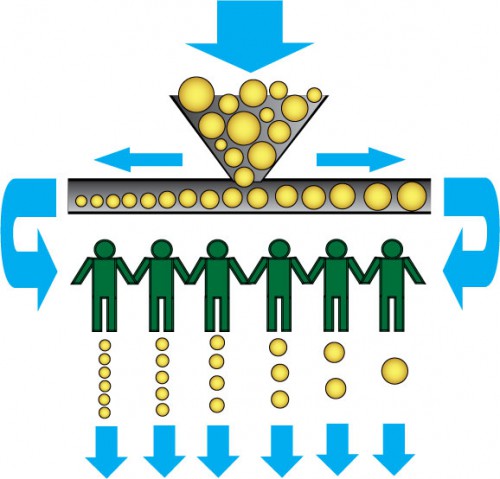
At the left side you have workers who do lots of small high availability tasks per period of time. At the right side you see persons who do only big tasks with high utilization.
In this case, you have only one pool of workers, but every worker has some weight to get assignment: on the left side are ones who do shortest, high availability tasks, on the right side are ones who do longest, high utilization tasks. When you put new task into the queue, you do sorting. After that, you assign new task, using simple procedure:
- Get task from left end of the queue
- Go to the first worker at left
- Try to assign the task (assignment subroutine):
- If chosen worker is free, then assign task to him and go to end of procedure
- Else go to next person at right
- Start assignment subroutine again
- End of procedure.
Mirror copy of such procedure can be used at right side of our double-queue. So you have auto-balancing here: you increase responsiveness and get bigger throughput at the same time. And the most important thing that procedure to manage such a queue is dumb.


